Github 原文:shareAI-lab/learn-claude-code
问题
我们在上文介绍了如何压缩上下文,但是压缩是会丢失很多细节的。例如,“用 tab 缩进不要用空格”可能被简化成”用户有代码风格偏好”。而且新开一个会话,连摘要也没了。
LLM 没有持久状态,所有信息都在上下文窗口里。上下文满了要压缩,压缩就有损。需要一层不参与压缩、跨会话保留的存储。
有没有办法能解决呢?有的兄弟,有的!这篇我们就来介绍这部分——记忆管线。
解决方案

这里相比之前,主要局势加入了一个记忆模块进入 Loop 循环,然后 LLm 的结果还会影响到这个模块的内容。这个记忆的存储选文件系统在.memory/ 目录下,每个记忆一个 .md 文件,带 YAML frontmatter(name / description / type)。文件多了就不好找,因此还需要一套索引:MEMORY.md 一行一个链接,注入 SYSTEM,就像 Mac 用户最喜欢的Spotlight功能一样。
我们都知道,人是有短期记忆、长期记忆、瞬时记忆等等多种记忆的,AI 也是如此!
| 类型 | 回答什么 | 示例 |
|---|---|---|
| user | 你是谁 | ”用 tab 不用空格” |
| feedback | 怎么做事 | ”别 mock 数据库” |
| project | 正在发生什么 | ”auth 重写是合规驱动” |
| reference | 东西在哪找 | ”pipeline bug 在 Linear INGEST” |
此外,索引是常驻 SYSTEM prompt(可被 prompt cache 缓存)的,文件内容按需注入到当前 user turn(按 filename/description 匹配当前对话,不破坏 cache)。写入由每轮结束后的提取器完成:用户显式说”记住”或表达稳定偏好时,提取器会保存为记忆。文件积累多了,定期整理去重。
工作原理
构建记忆
就像我上文说的一样,这个东西和 Mac 用户喜欢的 Spotlight 搜索一样,他是利用索引来实现快速搞准确的检索记忆的。
记忆存储
对人来说,记忆就是一种特殊的神经电信号,对 AI 来说,每个记忆是一个 .md 文件,YAML frontmatter 记录元数据:
---
name: user-preference-tabs
description: User prefers tabs for indentation
type: user
---
User prefers using tabs, not spaces, for indentation.
**Why:** Consistency with existing codebase conventions.
**How to apply:** Always use tabs when writing or editing files.记忆的索引
在记忆中,有一个叫做MEMORY.md 的文件,这是索引文件,一行一个链接:
- [user-preference-tabs](user-preference-tabs.md) — User prefers tabs for indentation和其他索引一样,当有新的内容进入,就会重新构建索引。
加载记忆
一般有 2 条路径来加载记忆,分别是依靠索引常驻和按需注入。
索引常驻系统提示词
就是说每次对话的时候刚才的索引文件都会进入系统提示词中,让 AI 获取到。不过为了节约 Token 消耗,这部分内容可以被缓存,一轮对话只需要加载一次。
相关记忆按需注入
每轮调用前,先把最近的对话和记忆的目录(包括:name 和 Description)一起发给 AI 然后做一次很简单的小生成,选出相关文件,其实还是走 skill 那套路子,如果有匹配的,那就去看一下原文,没有就跳过。
通常情况下,为了节省开销,最多只会注入最新的 5 条对话,不会注入更多。
相信从上一个文章中大模型 L4 压缩那里你就发现了,主要涉及到模型操作的东西,就要做好错误应对机制,在这里,如果这次简单的 side-query 失败了,那么就降级使用关键词匹配。
写入新记忆
刚才说过新记忆会重建索引,那么什么时候才要写入新的记忆呢?难道必须每次都要用户主动的说“记住 xxx”吗?
答案是否定的,在每轮对话结束时都会进行记忆写入,也就是没用再调用工具退出了 loop 循环时。
提取前先检查已有记忆,避免重复。提取 prompt 要求 LLM 返回 {name, type, description, body} 的 JSON 数组,只有确实有新信息时才写文件。
整理记忆
记忆会随着对话变多而不断积累,那么要怎么办?难道就看着它变成屎山吗?当然不是!
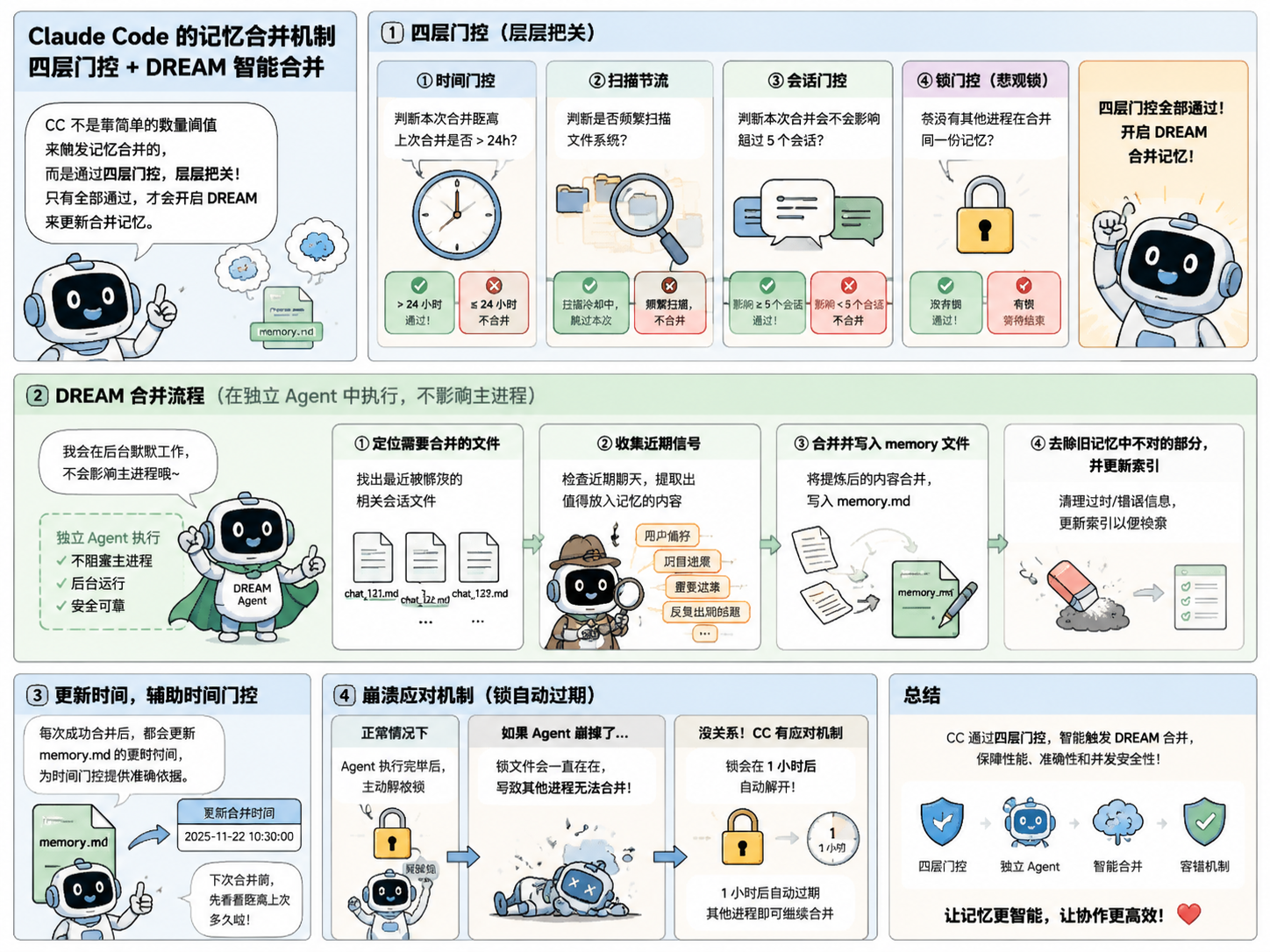
consolidate_memories() 在文件数达到阈值(默认 10)时触发,让 LLM 去重、合并矛盾、淘汰过时记忆,CC 把这个过程叫 Dream,实际有四层门控:时间间隔、扫描节流、会话数、文件锁。我们这里简化为文件数阈值。
记忆适合存什么
Memory 保存跨会话仍然有用的信息:用户偏好、反复出现的反馈、项目背景、常用入口和排查线索。它关注“以后还会用到什么”,并通过索引 + 按需加载把这些信息带回当前对话。
session memory 关注同一会话内的连续性:compact 之后,当前会话还需要保留哪些上下文。两者配合使用:Memory 管长期知识,session memory 管当前会话的压缩续接。
CC的记忆模块
CC 的记忆功能要比我们上面介绍的还要复杂很多,主要是有以下几个不同。
AI 选择记忆,而不是靠索引
CC 利用 AI 自己来选择记忆,而不是像我们刚才讲的,利用索引检索,其实就是匹配向量相似度,就是 RAG 的 embedding。步骤如下:
-
memoryScan.ts扫描.memory/下所有.md文件(排除 MEMORY.md),最多 200 个,按照更新时间从最新到最旧的顺序排序; -
把每个文件的 name和 description提取出来,做成一个列表;
-
发给 Sonnet side-query:“根据名称和描述选出真正有用的记忆(最多 5 个)。不确定就不要选。”
-
Sonnet 返回
{ selected_memories: ["file1.md", ...] }这个列表,告诉有哪些被挑出来了; -
选中文件读取完整内容(每文件 ≤ 200 行 / 4096 字节),注入上下文。单 session 总预算 60KB
Dream 机制
就是刚才说 CC 针对记忆的新增、合并去重的处理机制,不是靠简单的数量阈值来触发的,利用非常复杂的四层门控来实现:
-
时间门控:判断这次合并距离上次合并是否大于 24 小时,如果小于就不合并;
-
扫描节流:判断是否频繁扫描文件系统,避免记忆太多之后频繁扫描影响性能;
-
会话门控:判断这次合并后,会不会影响超过 5 个会话,如果小于 5 个,就不合并;
-
锁门控:有没有其他的在合并同一个记忆,这是个悲观锁,如果有其他的进程在合并,那就等待结束后再合并。
只有通过了这四层门控,才可以开启 DREAM 来更新合并记忆,这里还有几个注意事项:
-
这个更新记忆在 CC 中是有一个专门的 Agent 去做,不会影响主进程;
-
整个流程就是:
- 定位到哪些文件需要合并;
- 收集近期信号,检查一下近期的聊天有哪些可以放到记忆里面的东西;
- 合并并写入 memory 文件;
- 去除原有的旧记忆中不对的部分,并更新索引;
-
每次更新还会顺带修改更新时间,帮助做时间门控判断;
-
还是那个问题,涉及到 AI 操作了就得有错误应对,如果 Agent 崩掉了,但是因为锁的存在导致其他的进程无法写入那不是完了?没关系,CC 增加了一套应对机制,如果真的 Agent 崩掉了,那么这个锁会在 1 小时候自动解开,让其他进程可以在那之后再写入。
DREAM 机制确实是 CC 很复杂的一个东西,我这边做了个小漫画,来帮助你理解: