Github 原文:shareAI-lab/learn-claude-code
问题
我们都知道,AI 的上下文窗口是有限的。
Agent 跑着跑着,不动了——手里有 bash、有 read、有 write,能力是够的。但它读了一个 1000 行的文件(~4000 token),又读了 30 个文件,跑了 20 条命令。每条命令的输出、每个文件的内容,全都堆在 messages 列表里。
不压缩,Agent 根本没法在大项目里干活。
解决方案

整体来说还是保留了之前的 Loop 流程,但是增加了一个压缩管线和异常触发情况的处理。
在 message 交付给 LLM 模型之前,增加了一个压缩管线极致,这里与 CC 一样,有这4 个级别的压缩逻辑,这个我们后面慢慢讲,确保交付到 LLM 的信息可以防止上下文爆炸。同时,还增加了一种特殊情况,那就是大模型调用在调用工具之前,还没开始调用,新增的内容就给上下文干爆了,也就是说一次 Loop 循环都没结束就爆了,这种情况就要强行会在压缩管线前做压缩,然后再次交给大模型。
工作原理
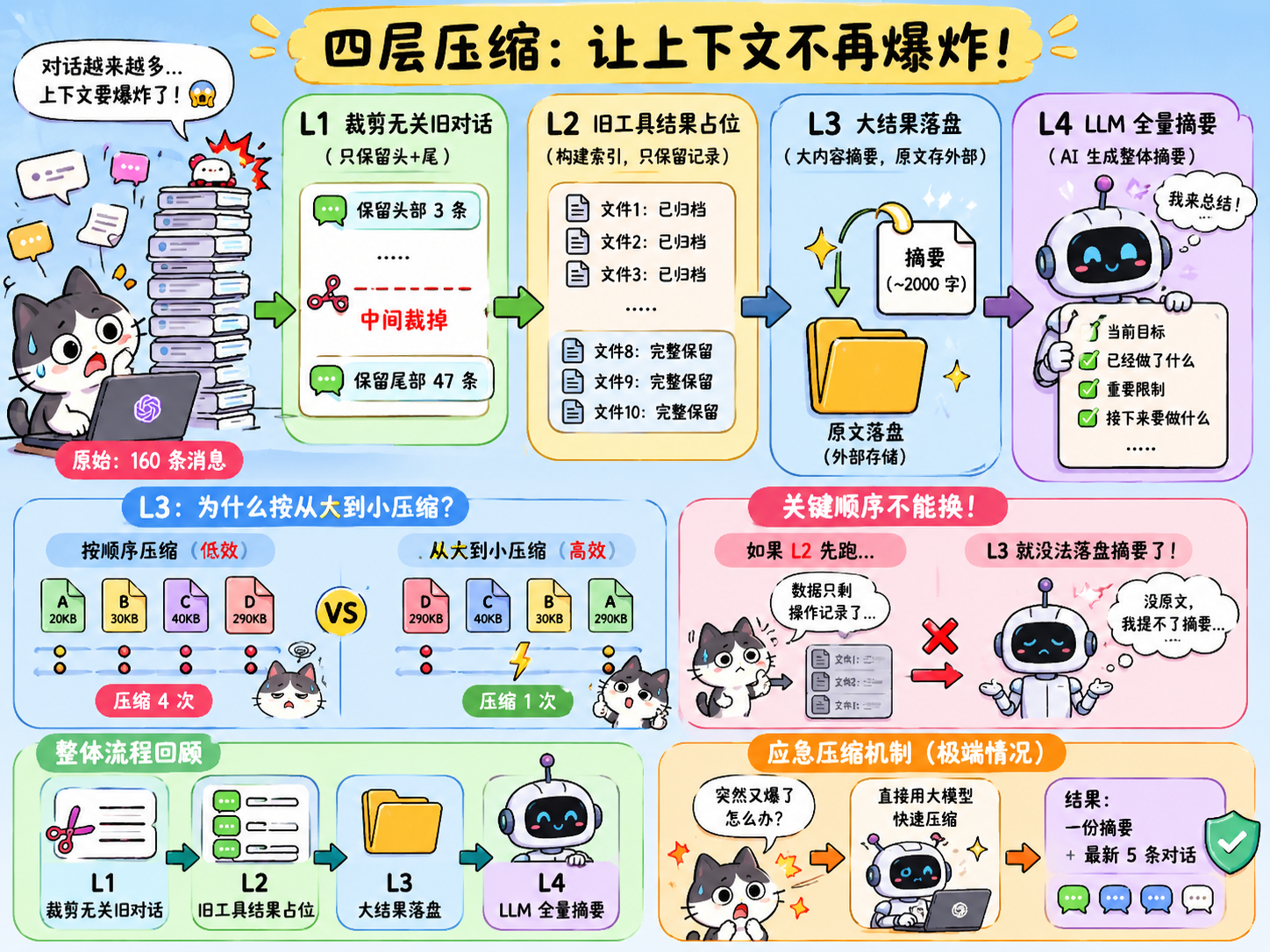
整体来说,是 4 层强度的压缩逻辑,并按照一个特定的顺序执行。
执行顺序
这些压缩方式按照如下图所示的顺序执行:

需要注意的是:这套顺序是不能换的!!!特别是 L3 和 L2 的顺序。
为什么?在后面我们介绍了之后你就会了解。
L1:裁剪无关旧对话
假如Agent 跑了 80 轮对话,messages 攒了 160 条,我们实际情况很大概率就会出现最前面的”帮我创建 hello.py”和当前工作几乎无关了,但全占着位置。L1 发现了这个问题,于是当消息数超过 50 条 → 保留头部 3 条(初始上下文)和尾部 47 条(当前工作),中间裁掉,就是说永远只有 50条信息,再多的差值就去掉中间的。
但请注意:裁掉了整条消息,但剩下的消息里 tool_result 内容仍在累积——例如,第 34 条消息里可能躺着 30KB 的旧文件内容,这些内容可以能依然站着巨大的上下文,这时候这些信息就需要用 L2 处理。
L2:旧工具结果占位
L2 专门来处理旧工具结果,方式类似于构建一套索引机制。
举个例子,假如说现在Agent 在最近的对话中,调用了查看文档的工具 10 次,经过 L1 压缩,他这部分工具调用结果依然没有被压缩,依然是这样的:
文件1 全文
文件2 全文
文件3 全文
文件4 全文
文件5 全文
文件6 全文
文件7 全文
文件8 全文
文件9 全文
文件10 全文10 个文件的全文在上下文里,简直是灾难!于是 L2 这么处理了:它沟建了一个类似索引的机制,十分类似 Skill 的渐进式披露,不同的是 Skill 是外挂的,需要的时候去查,这个是内置的,需要的时候重新打开,只保留曾经我调用过什么的操作记录。不过 L2 不会对最近 3 次对话的内容做压缩,确保效率。
文件1:已归档,需要再读请重新打开
文件2:已归档,需要再读请重新打开
文件3:已归档,需要再读请重新打开
文件4:已归档,需要再读请重新打开
文件5:已归档,需要再读请重新打开
文件6:已归档,需要再读请重新打开
文件7:已归档,需要再读请重新打开
文件8:完整保留
文件9:完整保留
文件10:完整保留利用这种方式,可以把全文在代码里面压缩为只有一行代码,极大的压缩了上下文。但是,这都是针对以前的一次只读了一个小文件的情况,如果我这次新的一次对话一口气就读了 1w 个文件,一个文件几百万的字符怎么办呢?上下文直接就爆炸了,L2 对新对话没压缩啊,别急,还有 L3.
L3:大结果落盘
如果说 L2 是把上下文压缩成了操作记录,需要的时候 AI 就再执行一遍操作,那么 L3 和 skill 就更接近了,它会把这些超级巨大的内容存为一段简短的摘要,一般2000 个字符,当模型需要的时候,实际的结果放到别的位置去,就顺着摘要去找原文去,和 Skill 十分类似不是吗?
但还没完,如果只是这样,还不够精妙。这时候想想,如果是有 4 个文件,加起来上下文容量已经超过了阈值 200K,需要压缩到 200k,那么我该按照什么顺序来压缩文件呢?
答案是从最大的文件开始压缩,然后是第二大的,依次往下。为什么?为了解答这个问题,不妨举个例子。
假如现在有 4 个文件,分别为 ABCD,他们的文件大小如下所示:
A 20KB
B 30KB
C 40KB
D 290KB我们几乎最先一定会想到,直接按照顺序压缩不就好了,好,那么我们就先这么来试试,很可能为了达到 200k 这个压缩目标,那么在落盘的时候,ABC 都进入了之后,都还没开始压缩,因为他们三个加起来只有 90K,没有达到 200K,只有 D 落盘才会突然超过需要触发压缩,也就是说罗盘操作 AI 要执行 4 次。
那么如果按照从大到小的顺序呢?D 最先罗盘,直接超过,AI 直接触发压缩,只需要触发一次!这就是区别!这在计算机算法领域是一个经典算法——贪心算法,永远优先处理最大的东西。
看到这里,我想你应该懂了为什么 L3 必须要在 L2 之前,因为我们上面说了,L2 是把旧内容只保留了一个操作记录,需要的时候重新执行,L3 是摘要落盘,如果 L2 先跑了,那些数据都没了,L3 直接没法落盘提取摘要了。
但是,从 L1 到 L3 其实都没有调用大模型的能力,你会发现他们都是基于判断的规则执行而已,也就是说其实 AI 并没有参与这个压缩过程,压缩全程也完全不知道压缩了什么,也不理解内容,在一些极端场景下,压缩后的上下文可能还是很大,这就需要 L4.
L4:LLM 全量摘要
L4 跟前三层不一样,它不是默认就直接触发的,是前三层全跑完了,但token 仍然超过阈值的情况下才会触发。
L4 就需要 AI 的参与了,其实也很简单,就是 AI 自己把这部分内容压缩成一份文本摘要,例如:
当前目标:正在改登录页
已经做了:改了按钮、修了弹窗、统一了紫色风格
重要限制:不要暗色,不要复杂,不要加文字
已改文件:Login.tsx、Button.tsx
接下来:检查移动端适配然后他会存一份完整聊天的备份,放在transcript里面。
完整步骤分为三步:
-
把完整聊天记录备份,放在刚才说的文件里面;
-
由 AI 总结摘要一份;
-
讲之前的完整聊天记录替换为这份摘要。
然后这里做了个熔断机制,就是如果 AI 连续三次压缩都失败了(例如出现网络问题等),那么就立即停止压缩,防止无意义的 Token 消耗。
应急压缩机制
如果 L4 失败了,或者 L4 压缩完还是超上下文了,那么只能是应急压缩了吃“保底”了。
这种应急压缩机制会直接利用大模型来压缩,最终的结果是:一份摘要(都是一份摘要,但是他会比 L4 压缩和精简的程度要狠很多,十分激进)+最新的 5 条对话,保留最新的防止 AI 彻底“断片儿”。
漫画图解
如果这些内容你觉得十分枯燥且难以理解,不妨看一下这幅漫画,我利用 Chat GPT 通过漫画的方式来图文并茂的解释问题: